FFT-method case validity
Fake News! Or is it?
If there is a lack of reliable data on the occurrence of specific events or knowledge on the consequences of decisions, there is a problem of uncertainty. Better decisions can hardly be achieved through the trained use of statistics or their transparent communication. Instead, the central question is how individual consumers can reduce uncertainty in their decision-making situation. Two scenarios are central here:
How can uncertainty be reduced (quickly, practically) for everyday problems in which consumers are left to their own devices?
How can uncertainty be reduced (quickly, practically) for everyday problems for which an expert provides advice to the consumer?
Why is it difficult to provide decision support for problems of uncertainty?
Decision problems of uncertainty are characterised by a lack of reliable data. This effectively rules out the direct selection of the best decision option. The support consists of identifying key strategies to reduce uncertainty. What do I need to ask to reduce the choice of potential information or options? What do I need to look for? What do I need to consider to sort out inappropriate options that do not meet the minimum requirements?
In contrast to consumers, experts in a particular subject area are able to identify objective shortfalls in the standard of a decision problem on the basis of fewer heuristic features. With the help of an analysis of specific consumer decision situations, possible expert heuristics are distilled into decision trees. These summarize the experts' gut feeling based on their experiences and provide consumers with a robust expertise that enables them, similar to the expert, to separate the wheat from the chaff.
This is not only important for issues where consumers are left to their own devices. Potential decision heuristics can also be combined in decision trees for consulting situations: Here it is a matter of asking the consultant the most important questions in order to be able to assess this situation robustly.
Fast-and-Frugal Trees (FFTs) are suitable decision trees that can be transparent, comprehensible to consumers and of high quality at the same time. These FFTs represent a sequence of features to be examined (Martignon et al., 2008). There is always only one branch (stop) or one arrives at the next test feature, but there are no further branches (see example below). This distinguishes the FFTs from the usual decision trees. Only the last feature in the chain has two branches.
It has been shown that FFTs enable fast and reliable decisions in various decision situations under uncertainty, e.g. in psychiatry, anaesthesiology, but also in the financial world (Aikman et al., 2014; Green & Mehr, 1997; Jenny et al., 2013). FFTs can be presented both digitally (e.g. app, website) and analogously to consumers (e.g. on posters or in brochures) in the form of a graphically illustrated, simple tree structure. This makes them an evidence-based instrument for decision support that is easy to implement. In the RisikoAtlas project it was developed and implemented for the first time for everyday consumer practice. The use of FFTs is also helpful because their application trains skills. The use of FFTs facilitates the internalisation of key characteristics for problems and stimulates critical thinking.
The order of features in an FFT is critical and must be determined in advance. There are both manual and more complex approaches using machine learning methods. Once statistically determined, this combination of features allows consumers to robustly classify decision options (e.g., whether an informed decision is possible) by independently examining those features.
How to construct a decision tree for a consumer problem - the FFT method of case-based feature validity
A. What do you need?
For the evidence-based development of FFTs, all approaches (including the FFT method of expert-based feature validity) require base data consisting of three parts: Characteristics of the problem, problem cases and the respective case assessment.
Part 1 – Characteristics of the problem
First, it is necessary to clarify what the problem is and to define the concrete decision or assessment on which information should be provided. What is the decision tree supposed to deliver? Under this aspect, potential features are researched with the help of experts (e.g. workshops), colleagues, laypersons and specialist literature (trade journals, white papers, government reports and experience reports). Potential features are all those characteristics of the problem situation that could possibly be an indicator of a good or bad decision regarding the problem. It may also be worthwhile to include new features such as one's own assumptions or intuitions. A list of potential features should then have been established.
Each potential feature must be comprehensible and testable by a layperson. Ideally, the list should summarize similar features, especially if there are too many of them. It is fair to say that expert supported feature selection is the most important tool in advance, particularly when it comes to cost-effective development. After all, each additional feature requires more cases in order to allow robust development. As a rule of thumb, you can basically calculate 20 to 50 cases for each feature. Each case requires effort: Each case must be individually coded for all features and an assessment must be obtained. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
Part 2 - Problem cases
Once you have made a selection of potential features, you need to find out how often and under what circumstances they occur in the real world. For this you collect material of typical decision situations, e.g. real purchase offers, videos of real consulting situations or real informational services.
If such case material of typical decision situations is not available, the FFT method of case-based feature validity is the method of choice. For this you have to consider how many candidate characteristics you want to examine, but also how rare the test object is, i.e. what the decision tree should help to identify. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
If such case material from typical decision situations is not available, the FFT method of case-based feature validity is not suitable. In such a case, you have to use a different method.
Part 3 - Case assessment
For each case in your data basis, you must know or determine whether the target criterion is met or not. In the case of health information, for example, a positive assessment would be the target criterion if it enables an informed decision, otherwise it would be a negative assessment. Without this basis of already determined profiles, no model for future decision support is possible. One approach would be to test each case, i.e. determine how it turned out. Very often, this effort is not feasible, because that would mean investigating 500 to 700 cases experimentally.
The alternative is then the "view of the expert", on which the model approach presented here was aimed from the outset. Several independent experts evaluate each individual case with a view to the goal of the development, e.g "Does this health information allow an informed decision?" Their assessment must then be combined. The median of their judgements proves to be more robust than arithmetic averages when combining the individual assessments. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
B. How do you proceed?
You now have to find out which features the selected cases (for example, real purchase offers) show or do not show. During describing your cases in terms of the potential features, you learn a lot about the actual testability of the features by laypeople. It can be assumed that you will subsequently remove some features for which examination by the consumers would have been difficult.
Parallel to the coding of the cases in the features the expert evaluations are "collected". Experts receive only the case material, never the features or even the feature coding. The aim is to model the expert assessments independently (the expert's view).
As the coding of numerous potential features is very complex, an early point in time of a further reduction of the number of features promises great efficiency gains. However, before making a selection with the help of laypeople by testing how well they understand the features, a statistical approach is usually less costly and easier. A simple statistical feature selection is worthwhile after just 100 cases. Various tools are available, e.g. the boruta package or the caret package (both implemented in the open source solution R). With boruta, the basic meaning of the individual features is checked by so-called random forests. If a feature behaves like a random number with regard to the expert assessments, the statistical recommendation is to leave it aside due to lack of significance in further development. As with all statistical approaches based on random sampling, this also applies here: If your background knowledge tells you that the feature should actually be significant, test it in another round and also code it in the next 100 cases.
Repeat this process of coding, assessing, and statistical feature selection every 100 cases and try to make the set of features more manageable. This has a positive effect on the coding effort, the expert assessments and also on the model finding.
If nothing changes during feature selection, if you have assessed 500 to 1000 cases depending on the number of features, or if you run the risk of falling below six features, it is worth modeling the decision tree on the basis of these case-feature assessment profiles.
The pipeline for development can be summarized in a simplified illustration:

Modeling from tree development and cross-validation can be performed manually, but in the sense of effective modeling it is easier with the open source solution R. In addition to the FFTrees package (Phillips et al., 2017), you can also download a web solution by Evaldas Jablonskis and Uwe Czienskowski from http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/. If you need assistance with this, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
You will model a Fast-and-Frugal Tree (FFT) using the portion of cases you select as training data; often 50% to 80% of cases. This FFT has a certain ability to make the right decisions (assessment). This means it will overlook cases in the real world and give false alarms on others. To quantify this ability, either perform a statistical cross-validation (you apply the decision tree to randomly repeated cases; test data cases) or apply it once to a collection of cases with assessments that you set aside before modeling (20% to 50% of the data).Alternatively, you can collect a completely new sample of cases with feature codings and assessments (out-of-sample) to which you apply the decision tree (additional time and effort).
Which quality is sufficient depends very much on the types of errors and the costs associated with the error. Finally, the model must be tested in practice with laypeople. Here, a randomised controlled study is useful. It compares the decision intentions of consumers who are given the decision tree with those who have nothing or a standard information sheet. If you need assistance with the assessment or quality, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
- Aikman, D., Galesic, M., Gigerenzer, G., Kapadia, S., Katsikopoulos, K. V., Kothiyal, A., ... & Neumann, T. (2014). Taking uncertainty seriously: Simplicity versus complexity in financial regulation. Bank of England Financial Stability Paper, 28.
- Green, L., & Mehr, D. R. (1997). What alters physicians' decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219–226.
- Jablonskis, E., & Czienskowski, U. (2017). Decision trees online. http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/
- Jenny, M. A., Pachur, T., Williams, S. L., Becker, E., & Margraf, J. (2013). Simple rules for detecting depression. Journal of Applied Research in Memory and Cognition, 2(3), 149–157.
- Luan, S., Schooler, L. J., & Gigerenzer, G. (2011). A signal-detection analysis of fast-and-frugal trees. Psychological Review, 118(2), 316.
- Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352–361.
If you would like to adopt a consumer topic from our website, you can do so in the following three ways:
- You are using a digital copy. Either you directly save an illustration or download our PDF, or you integrate the illustration via Link(a href) or iframe.
- You take your analogue copy and print out our PDF. The resolution and vector-based graphic is suitable for posters and brochures.
- You recommend the app and refer to the Risikokompass from the PlayStore and AppStore.
If you would like to develop your own model, please consult the final report on the RiskAtlas project from July 2020 or contact us. Contact details can be found here.
When using the instruments, please mention the funding agency, which is the German Federal Ministry of Justice and Consumer Protection, and the Harding Centre for Risk Literacy as the responsible developers.
Logos can be downladed here.
FFT-Methode getesteter Merkmalsvalidität
In the 2016 US election, the 20 most successful false news reports were more often liked, shared or commented on than the 20 most successful articles by serious media. This example shows for one: Nowadays, the Internet makes it much easier to distribute information quickly. Secondly, it shows that fake news is often more attractive than serious reporting. This leads to misjudgements, rigid discussion fronts and thus makes social exchange more difficult. It's not always easy to recognise fake news. In a first step it is therefore important for you to be able to distinguish between a piece of news reporting and an opinion text. Which text presents facts - and which one does not? Can you recognise a satire, a commentary or a gloss? Our decision tree is a digital checklist that helps you to check a news text and warns you about any doubts.
When do I need this figure?
If you search for supposed news, receive them from others, or encounter them in digital groups, it is appropriate to check whether the texts are an opinion format or an actual news piece.
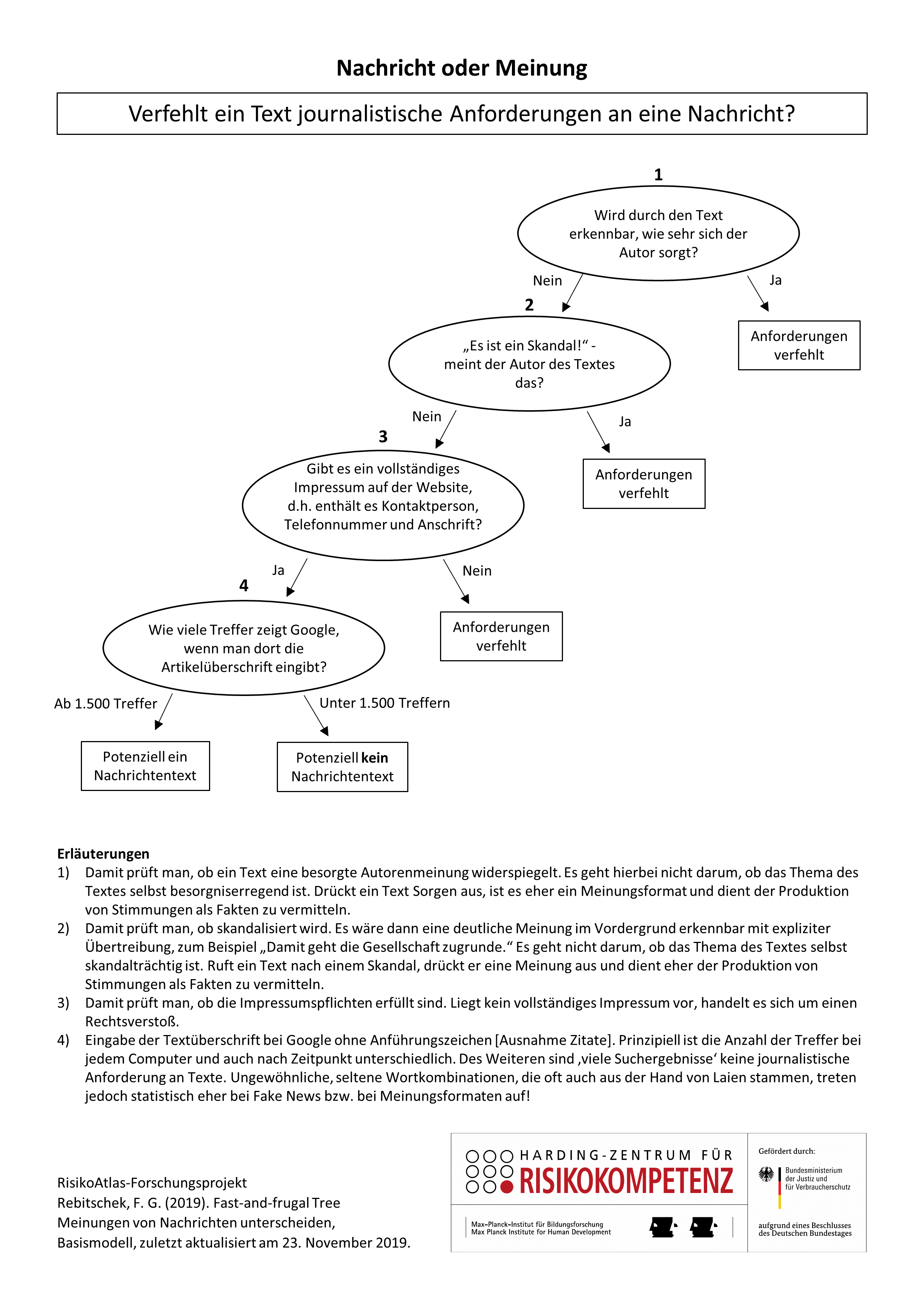
You can also check this text more extensively. Please note, however, that no text or checklist is ever perfect. With each additional feature that you check, the risk of an incorrect assessment of the text increases.
Further features are:
- Is a fact exaggerated without providing explanations [NEGATIVE FEATURE, i.e. if this occurs, journalistic requirements for a news report are not fulfilled]?
- Is there an explicit claim that the text reveals a secret [NEGATIVE FEATURE]?
- Is it claimed that other media hide the truth or lie [NEGATIVE FEATURE]?
- Are personal pronouns such as "you", "we", "us", "your" [NEGATIVE FEATURE] used in the text, outside of quotations?
What does the figure show?
The figure shows a decision tree that you can use to check German-language texts that give the impression of a purely fact-based journalistic piece of news. Here you check whether this text meets journalistic standards for written news reportings.
A warning means that the text does not meet those standards at all. The text that you have checked does not provide information in the sense of news reporting. There can be many reasons for this: It may be because essential information is withheld. It may be advertising or designed unprofessionally. It can be another type of text, e.g. one that relies on opinion (comment) or a satirical format. However, the text can also be simply unprofessional or it is so-called fake news. This is especially true if it intentionally appeals to the emotions of the reader. In some cases, the decision tree can come to a wrong conclusion.
An "all-clear" means that journalistic key requirements are met to a large extent. It can be assumed that the text is not fake news.
It is not strictly necessary to check further requirements beyond the features of the decision tree. Studies of the underlying texts show that other important requirements or features are usually fulfilled or not fulfilled.
Where is the data that the decision tree is based on coming from?
Cases – Which texts served as a basis?
600 texts from German-language websites were compiled. They were researched by experts from the Harding Center for Risk Literacy. Since we are interested in the detection of fake news, a topic-based strategy was chosen. The topics on which both news and opinion formats were to be expected came from Correctiv[1] and from Faktenfinder[2]. They were then researched with the following keywords: "Angela Merkel", "refugees", "asylum", " migrant background", "chemtrails", "contrails", "Islam", "Muslims", "Israel", "Jews", "cancer", "unemployed", "gender", "Russia", "VW", "left-wing extremism", " autonomists", "right-wing extremism", "cash", "climate". This research was carried out on Bing-News, Google-News, Facebook, Twitter and with the help of Google's "auto-complete function". In addition, the sample was enriched by individual texts from sources that were thematized as fake news portals in the classic high-reach news portals.
TV recommendations and videos were removed, as were reports and interviews.
Target assessment – How was the fulfillment/non-fulfillment of journalistic standards in news reportings determined?
18 journalists with professional experience in print and digital media assessed the cases.
Each text was assessed by three experts with regard to the question: "Does this text fulfil the journalistic standards for a message? A four-step answer format was used. The median value of three experts each was used as the target value for the individual case. The experts did not receive any information about the potential features used in the study.
The derived warnings or "all-clears" then appear in the decision tree if the journalistic requirements for a news text are not met at all or at least partially within the framework of this expert model. In addition, an explanation is given.
Potential features – Which features were considered?
Based on various sources (ARD MEDIATHEK, 2017; BR.de, 2017; Brown, 2015; Bundeszentrale für politische Bildung, 2017; Erb, 2017; Focus.de, 2015; Kolonko, 2017; La Roche, 2005; Rack et al., 2017; Shu et al., 2017) 86 features were collected, 50 of which were regarded as generally testable by laypeople.
Selection of features and modelling
The purpose of pre-selecting features was to limit the number of candidates for the decision tree to distinguish between news texts and opinion texts. The feature selection was performed from two points of view: Lay testability and statistical significance; in six steps:
- Cases 1–100 were coded, compared, discussed and harmonised by two independent research assistants in 50 features. A statistical feature selection was then performed (using Random Forest Trees with boruta in the statistical program R) and different features were eliminated due to feedback of the coders (were found to be too difficult to use by laypeople). 20 features remained.
- Cases 101–500 were were coded, compared, discussed and harmonised in groups of 100 by two independent assistants. Four further statistical feature selections were performed. 15 features remained.
- Cases 501–600 were used to check the coding behaviour of laypeople against a practiced research assistant. Five Clickworkers each did not achieve a satisfactory agreement on five features. The statistical feature selection did not change anything.
The model
On the model shown above – filtering extreme opinion formats.
The model refers to texts in which experts completely rule out the possibility that they meet journalistic requirements for a news text. Both, the recursive algorithm by Marcus Buckmann and Özgür Simşek (manuscript in preparation) and the FFTrees package (Phillips et al., 2017) were used for model identification. The ifan algorithm was used to optimise for balanced accuracy.
What is the quality of the model?
The data (collected cases of news-like texts) were collected between 2017 and 2018 and coded in their features and assessed by experts. 558 cases were complete. The datasets were randomly divided into training datasets (two thirds) and test datasets (one third). The models have the following quality:
The model for recognising texts that do not meet journalistic standards for news is of the following quality:
A cross validation of the identified decision tree resulted in the following quality measures: balanced accuracy = 0.76; sensitivity in the recognition of texts that do not meet any kind of standards for news texts (share of 21% in the test set), of 0.88. This means that 88 out of 100 of such texts that are definitely not news were detected by the decision tree.
The specificity in the confirmation of news and hybrid forms is 0.64.
Potential for development
- Continuous further development of the underlying training data due to changes in availability
- Higher share of health information collected by laypeople in order meet the actual searching and finding behaviours
Empirical evaluation with consumers
All research results on the fundamentals and on the effectiveness of the RiskoAtlas tools in terms of competence enhancement, information search and risk communication will be published together with the project research report on 30 June 2020. If you are interested beforehand, please contact us directly (Felix Rebitschek, rebitschek@mpib-berlin.mpg.de).
Sources
- ARD MEDIATHEK (2017): Fakt oder Fake? Wie man gefälschten Nachrichten auf die Schliche kommt. Verfügbar unter: https://www.ardmediathek.de/tv/neuneinhalb-das-Reportermagazin-f%C3%BCr-Ki/Fakt-oder-Fake-Wie-man-gef%C3%A4lschten-Na/Das-Erste/Video?bcastId=431486&documentId=41134052 (letzter Abruf am 19.06.2018).
- BR.de (2017). So geht Medien (letzter Zugriff, 23.03.2017).
- Brown, P. (2015). Sechs Wege um Falschmeldungen zu entlarven. Der Freitag, 28.10.2015 (letzter Abruf am 23.03.2017).
- Bundeszentrale für politische Bildung (2017). Den Durchblick behalten. So lassen sich Fake News enttarnen, 23.02.2017 (letzter Abruf am 23.03.2017).
- cf. Shu, K., Sliva, A., Wang, S., Tang, J., & Liu, H. (2017). Fake news detection on social media: A data mining perspective. ACM SIGKDD Explorations Newsletter, 19(1), 22–36.
- Erb, S. (2017). So entlarven Sie Fake News, 31.07.2017 (letzter Abruf am 14.2.2017).
- Focus.de (2017). Unseriöse Quellen: So enttarnen Sie Fake News. Online focus, 11.10.2017 (letzter Abruf am 24.03.2017).
- Kolonko (2017). Wie erkenne ich Fake News? Hilfreiche Tipps für die Faktenprüfung. Planet Wissen.
- La Roche, W. V. (2006). Einführung in den praktischen Journalismus. München, List.
- nach Computer + Unterricht 74/2009, S. 43 und FH Hannover: Handbuch zur Recherche. Hannover 2006.
- Rack et al. (2017). Fakt oder Fake? Wie man Falschmeldungen im Internet entlarven kann. klicksafe.de to go.
Last update: 27 November 2019.