FFT-method model
All that glitters is not gold - User reviews should be read with caution
If there is a lack of reliable data on the occurrence of specific events or knowledge on the consequences of decisions, there is a problem of uncertainty. Better decisions can hardly be achieved through the trained use of statistics or their transparent communication. Instead, the central question is how individual consumers can reduce uncertainty in their decision-making situation. Two scenarios are central here:
How can uncertainty be reduced (quickly, practically) for everyday problems in which consumers are left to their own devices?
How can uncertainty be reduced (quickly, practically) for everyday problems for which an expert provides advice to the consumer?
Why is it difficult to provide decision support for problems of uncertainty?
Decision problems of uncertainty are characterised by a lack of reliable data. This effectively rules out the direct selection of the best decision option. The support consists of identifying key strategies to reduce uncertainty. What do I need to ask to reduce the choice of potential information or options? What do I need to look for? What do I need to consider to sort out inappropriate options that do not meet the minimum requirements?
In contrast to consumers, experts in a particular subject area are able to identify objective shortfalls in the standard of a decision problem on the basis of fewer heuristic features. With the help of an analysis of specific consumer decision situations, possible expert heuristics are distilled into decision trees. These summarize the experts' gut feeling based on their experiences and provide consumers with a robust expertise that enables them, similar to the expert, to separate the wheat from the chaff.
This is not only important for issues where consumers are left to their own devices. Potential decision heuristics can also be combined in decision trees for consulting situations: Here it is a matter of asking the consultant the most important questions in order to be able to assess this situation robustly.
Fast-and-Frugal Trees (FFTs) are suitable decision trees that can be transparent, comprehensible to consumers and of high quality at the same time. These FFTs represent a sequence of features to be examined (Martignon et al., 2008). There is always only one branch (stop) or one arrives at the next test feature, but there are no further branches (see example below). This distinguishes the FFTs from the usual decision trees. Only the last feature in the chain has two branches.
It has been shown that FFTs enable fast and reliable decisions in various decision situations under uncertainty, e.g. in psychiatry, anaesthesiology, but also in the financial world (Aikman et al., 2014; Green & Mehr, 1997; Jenny et al., 2013). FFTs can be presented both digitally (e.g. app, website) and analogously to consumers (e.g. on posters or in brochures) in the form of a graphically illustrated, simple tree structure. This makes them an evidence-based instrument for decision support that is easy to implement. In the RisikoAtlas project it was developed and implemented for the first time for everyday consumer practice. The use of FFTs is also helpful because their application trains skills. The use of FFTs facilitates the internalisation of key characteristics for problems and stimulates critical thinking.
The order of features in an FFT is critical and must be determined in advance. There are both manual and more complex approaches using machine learning methods. Once statistically determined, this combination of features allows consumers to robustly classify decision options (e.g., whether an informed decision is possible) by independently examining those features.
How to construct a decision tree for a consumer problem - the FFT method of expert feature validity
A. What do you need?
For the evidence-based development of FFTs, all approaches (including the FFT method model) require base data consisting of three parts: Characteristics of the problem, problem cases and the respective case assessment. The FFT method model is helpful if there is already a model of the decision goal of interest, e.g. a decision tree created by other researchers (Banerjee et al., 2017).
Part 1 – Characteristics of the problem
If a model is already available, the features used are usually also known (with the exception of certain deep learning approaches, which have not been particularly widespread for consumer problems until 2019). Each potential feature must be understandable and testable by a layperson. Internationally developed models in particular require a separate examination not only of the German language, but also of the cultural transfer to the German consumer world and the design of information or advice.
Part 2 - Problem cases
If a model already exists, a test data set is required for its empirical scientific verification, e.g. a collection of real decision situations such as real purchase offers, videos of real consulting situations or real informational offers.
With regard to the number of potential features and the rarity of the test object (what should the decision tree help to identify?), a systematic approach should be used to select samples of decision situations that are as ecologically valid as possible. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
Part 3 - Case assessment
In order to test the model, you must know whether the target criterion is met or not for each case in your data basis. In the case of health information, for example, a positive assessment would be the target criterion if it enables an informed decision, otherwise a negative assessment.
Without this basis of cases that have already been decided, you cannot test the model or use your own model to model it after the original model.
One approach would be to test each case, i.e. determine how it turned out. Very often, this effort is not feasible, because that would mean investigating 500 to 700 cases experimentally. The alternative is then the "view of the expert", on which the model approach presented here was aimed from the outset. Several independent experts evaluate each individual case with a view to the goal of the development, e.g "Does this health information allow an informed decision?" The median of their judgements proves to be more robust than arithmetic averages when combining the individual assessments. If you need support during this process, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
B. How do you proceed?
By having the cases of your test data set coded in the features of the original model, you learn a lot about the limited testability of some features by laypeople. However, it can be assumed that you will keep all the features that make up the model so that you can test it. For the same reason, there is no statistical feature selection.
Parallel to the coding of the cases in the features, the cases are to be tested, or the expert evaluations "collected" for your test data set. Experts receive only the case material, never the features or even the feature coding. The aim is to model the expert assessments independently (the expert's view).
Depending on the number of features, this process of coding and assessing can be completed after 200 to 600 cases, and the model is tested on the data set that you have generated yourself.
The pipeline for development can be summarized in a simplified illustration:
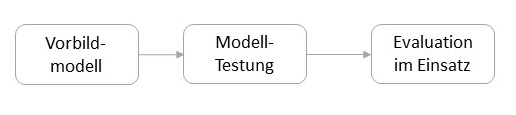
Modeling from tree development and cross-validation can be performed manually, but in the sense of effective modeling it is easier with the open source solution R. In addition to the FFTrees package (Phillips et al., 2017), you can also download a web solution by Evaldas Jablonskis and Uwe Czienskowski from http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/. If you need assistance with this, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
You will construct the model manually and check it against the generated test data set. You perform a cross-validation and apply the model to randomly repeated cases from the test data set.
Additionally or alternatively, you model a Fast-and-Frugal Tree (FFT) that is intended to mimic the model, but is probably simpler from the consumer's point of view. Then you would select part of the data set as training data; often 33% or 50% of the cases. This FFT has a certain quality in terms of tracking down your target feature (assessment). This means it will overlook cases in the real world and give false alarms on others. To quantify this quality, perform a statistical cross-validation or apply it once to a collection of cases with assessments that you put aside before modeling. Alternatively, you can collect a completely new sample of cases with feature codings and assessments (out-of-sample) to which you apply the decision tree (additional time and effort).
Which quality is sufficient depends very much on the types of errors and the costs associated with the error. Finally, the model and, if necessary, the new FFT must be tested in practice with laypeople. Here, a randomised controlled study is useful. It compares the decision intentions of consumers who are given the decision tree with those who have nothing or a standard information sheet. If you need assistance with the assessment or quality, please consult the final report on the Risk Atlas project from July 2020 or contact us. Contact details can be found here.
- Aikman, D., Galesic, M., Gigerenzer, G., Kapadia, S., Katsikopoulos, K. V., Kothiyal, A., ... & Neumann, T. (2014). Taking uncertainty seriously: Simplicity versus complexity in financial regulation. Bank of England Financial Stability Paper, 28.
- Banerjee, S., Chua, A. Y., & Kim, J. J. (2017). Don't be deceived: Using linguistic analysis to learn how to discern online review authenticity. Journal of the Association for Information Science and Technology, 68(6), 1525–1538.
- Green, L., & Mehr, D. R. (1997). What alters physicians' decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219–226.
- Jablonskis, E., & Czienskowski, U. (2017). Decision trees online. http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/
- Jenny, M. A., Pachur, T., Williams, S. L., Becker, E., & Margraf, J. (2013). Simple rules for detecting depression. Journal of Applied Research in Memory and Cognition, 2(3), 149–157.
- Luan, S., Schooler, L. J., & Gigerenzer, G. (2011). A signal-detection analysis of fast-and-frugal trees. Psychological Review, 118(2), 316.
- Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352–361.
If you would like to adopt a consumer topic from our website, you can do so in the following three ways:
- You are using a digital copy. Either you directly save an illustration or download our PDF, or you integrate the illustration via Link(a href) or iframe.
- You take your analogue copy and print out our PDF. The resolution and vector-based graphic is suitable for posters and brochures.
- You recommend the app and refer to the Risikokompass from the PlayStore and AppStore.
If you would like to develop your own model, please consult the final report on the RiskAtlas project from July 2020 or contact us. Contact details can be found here.
When using the instruments, please mention the funding agency, which is the German Federal Ministry of Justice and Consumer Protection, and the Harding Centre for Risk Literacy as the responsible developers.
Logos can be downladed here.
Suppose you need a new backpack for hiking. You don't really know anything about backpacks. Since you have the widest choice online, you decide to buy the product on the Internet. The manufacturer's descriptions all sound the same and promise similar things to you. Since you really don't know what to watch out for when buying, you filter by customer ratings. After all, buying a product that only has five-star ratings cannot be a mistake. Or can it?
When shopping online, customer reviews are the most important decision criterion - even before price comparisons or recommendations by friends or relatives. But all too often these reviews are fake. It is estimated that every fifth review is not real. The review business is booming. At relevant agencies a paid review does not cost much more than 10 Euros. Fortunately, there are some criteria by which you can recognize false recommendations. Our decision tree as a digital checklist should help you to distinguish real reviews from fake ones.
Who is this decision tree for?
For all consumers who shop online.
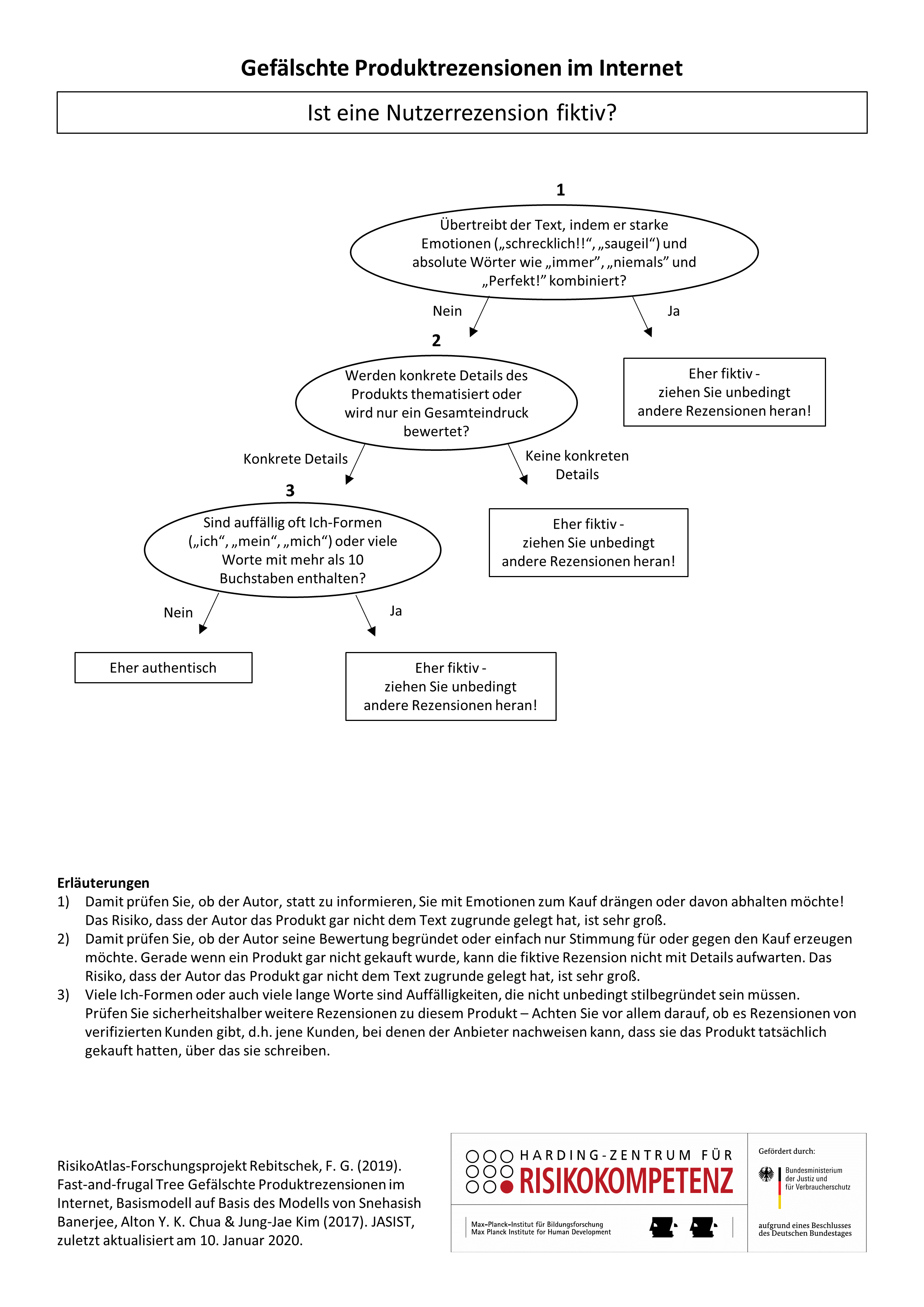
You can also examine the user review further.
However, please note that no test or checklist is ever perfect.With every additional feature that you check, the risk of an incorrect assessment of the text increases. For example, you could check user reviews and user ratings with an automatic tool: www.reviewmeta.com. Although the site is in English, you can check German Amazon product links there, for example. In this way you can see how high the real rating is and which reviews are not trustworthy.
Where is the data coming from?
Cases – Which served as a basis?
Data from a study by the Harding Center of Risk Literacy served as a test data set.
Target assessment – How were the product reviews pre-assessed?
Product reviews were created for the modelling in a study by the Harding Center of Risk Literacy, and created artificially in another study by laypeople.
Potential features – Which features were considered?
Three features from Banerjee et al.'s (2017) model were used.
Selection of features and modelling
Three features from Banerjee et al.'s (2017) model were used.
The model
The FFTrees package was used for model identification (Phillips et al., 2017). The ifan algorithm was used to optimize for balanced accuracy.
What is the quality of the data?
Since the evaluation studies run until December 2019, no predictions can yet be made for the quality of the English-language model for product reviews in German.
Potential for development
Continuous further development of the underlying training data due to changes in the market situation.
Empirical evaluation with consumers
All research results on the fundamentals and on the effectiveness of the RiskoAtlas tools in terms of competence enhancement, information search and risk communication will be published together with the project research report on 30 June 2020. If you are interested beforehand, please contact us directly (Felix Rebitschek, rebitschek@mpib-berlin.mpg.de).
Sources
• Banerjee, S., Chua, A. Y., & Kim, J. J. (2017). Don't be deceived: Using linguistic analysis to learn how to discern online review authenticity. Journal of the Association for Information Science and Technology, 68(6), 1525-1538.
• Phillips, N. D., Neth, H., Woike, J. K., & Gaissmaier, W. (2017). FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgment and Decision making, 12(4), 344-368.
Last update: 27 November 2019.
Recognising fake online stores
Informed telematics rate selection
Inkassobescheide prüfen
Vergleichsportale