Methode FFT Fall-Validität
Fake News! Oder doch nicht?
Mangelt es an belastbaren Daten zum Eintreffen spezifischer Ereignisse oder an Wissen über Entscheidungskonsequenzen, liegt ein Problem der Unsicherheit vor. Bessere Entscheidungen können dabei kaum durch den geübten Umgang mit Statistiken oder ihre transparente Kommunikation erreicht werden. Stattdessen ist die zentrale Fragestellung, wie der einzelne Verbraucher die Unsicherheit in seiner Entscheidungssituation reduzieren kann. Hierbei sind zwei Szenarien zentral:
Wie kann Unsicherheit für Problemstellungen alltagstauglich (schnell, praktisch) reduziert werden, bei denen der Verbraucher auf sich allein gestellt ist?
Wie kann Unsicherheit für Problemstellungen alltagstauglich (schnell, praktisch) reduziert werden, bei denen ein Experte dem Verbraucher Rat gibt?
Warum ist es schwierig, Entscheidungsunterstützung bei Problemen der Unsicherheit zu geben?
Entscheidungsprobleme der Unsicherheit zeichnen sich durch einen Mangel an belastbaren Daten aus. Dadurch ist eine direkte Auswahl der besten Entscheidungsoption im Grunde ausgeschlossen. Die Unterstützung besteht darin, entscheidende Strategien zu kennen, um Unsicherheit zu reduzieren. Was muss ich fragen, um die Auswahl möglicher Informationen bzw. Optionen zu reduzieren? Wonach muss ich suchen? Was muss ich prüfen, um unpassende Optionen auszusortieren, welche die Mindestanforderungen nicht erfüllen?
Im Gegensatz zu Verbrauchern sind Experten in einem bestimmten Fachgebiet in der Lage, anhand weniger heuristischer Merkmale objektive Standardunterschreitungen bei einem Entscheidungsproblem zu identifizieren. Mithilfe einer Analyse von konkreten Entscheidungssituationen von Verbrauchern werden mögliche Expertenheuristiken in Entscheidungsbäume destilliert. Diese fassen das auf Erfahrung basierte Bauchgefühl der Experten zusammen und leihen dem Verbraucher eine robuste Expertise, mit der er, dem Experten ähnlich, die Spreu vom Weizen zu trennen vermag.
Dies ist nicht nur für Fragestellungen bedeutsam, bei denen Verbraucher auf sich allein gestellt sind. Auch für Beratungssituationen lassen sich mögliche Entscheidungsheuristiken in Entscheidungsbäumen kombinieren: Hier geht es darum, dem Berater die wichtigsten Fragen zu stellen, um diese Situation robust einschätzen zu können.
Geeignete Entscheidungsbäume, die transparent, für Verbraucher nachvollziehbar und zugleich von hoher Güte sein können, sind die Fast-and-Frugal Trees (FFTs). Diese FFTs stellen eine Abfolge von zu prüfenden Merkmalen dar (Martignon et al., 2008). Es gibt immer nur eine Abzweigung (Stopp) oder man kommt zum nächsten Prüfmerkmal, aber es gibt keine weiteren Verzweigungen (s.u. das Themenbeispiel). Dies unterscheidet die FFTs von üblichen Entscheidungsbäumen. Erst beim letzten Merkmal in der Kette gibt es zwei Abzweigungen.
Es wurde gezeigt, dass FFTs in verschiedensten Entscheidungssituationen unter Unsicherheit schnelle und zuverlässige Entscheidungen ermöglichen, u.a. in der Psychiatrie, in der Anästhesiologie, aber auch in der Finanzwelt (Aikman et al., 2014; Green & Mehr, 1997; Jenny et al., 2013). FFTs lassen sich in Form einer grafisch aufgearbeiteten, einfachen Baumstruktur sowohl digital (z.B. App, Internetseite) als auch analog zu den Verbrauchern bringen (z.B. auf Postern oder in Broschüren). Somit sind sie ein evidenzbasiertes Instrument zur Entscheidungsunterstützung, das einfach zu implementieren ist. Im RisikoAtlas-Projekt wurde es erstmals für die alltägliche Verbraucherpraxis entwickelt und umgesetzt. Der Einsatz der FFTs ist zudem lebensdienlich, da ihre Benutzung Fähigkeiten trainiert. Die Verwendung der FFTs erleichtert das Verinnerlichen von Schlüsselmerkmalen für Problemstellungen und regt kritisches Denken an.
Die Reihenfolge der Merkmale in einem FFT ist kritisch und muss aufwendig im Vorhinein ermittelt werden. Hierbei sind manuelle, aber auch komplexere Ansätze mithilfe der Methoden des maschinellen Lernens vorhanden. Einmal statistisch ermittelt, ermöglicht diese Merkmalskombination einem Verbraucher, Entscheidungsoptionen robust zu klassifizieren (z.B. dahingehend, ob eine informierte Entscheidung ermöglicht wird), indem er die Ausprägung der Merkmale eigenständig überprüft.
Wie konstruiert man einen Entscheidungsbaum für ein Verbraucherproblem – die FFT-Methode fallbasierter Merkmalsvalidität
A. Was benötigen Sie?
Für die evidenzbasierte Entwicklung von FFTs benötigt man bei allen Ansätzen (inkl. der FFT-Methode fallbasierte Merkmalsvalidität) eine Datenbasis mit drei Teilen: Merkmale des Problems, Fälle der Problemstellung und die jeweilige Fallbewertung.
-
Teil – Merkmale des Problems
Es ist zunächst erforderlich zu klären, was das Problem ist, und zu definieren, über welche konkrete Entscheidung oder Bewertung informiert werden soll. Was soll der Entscheidungsbaum liefern? Unter diesem Gesichtspunkt recherchiert man mithilfe von Experten (z.B. Workshops), Kollegen, Laien und der Fachliteratur (Fachzeitschriften, White Papers, Regierungs- bis hin zu Erfahrungsberichten) Kandidatenmerkmale. Kandidatenmerkmale sind all jene Eigenschaften der Problemsituation, die möglicherweise ein Indikator für eine gute oder schlechte Entscheidung bei dem Problem sein könnten. Es kann lohnenswert sein, auch neue Merkmale, eigene Vermutungen, Intuitionen hinzuzuziehen.
Jedes Kandidatenmerkmal muss durch einen Laien verstehbar und prüfbar sein. Die Liste sollte idealerweise ähnliche Merkmale zusammenfassen, gerade wenn es zu viele Merkmale werden. Man kann sagen, dass die von Experten gestützte Merkmalsauswahl im Vorhinein die wichtigste Stellschraube ist, vor allem um kosteneffektiv zu entwickeln. Denn jedes Merkmal zusätzlich verlangt mehr Fälle, um eine robuste Entwicklung zu ermöglichen. Als Faustregel kann man im Grunde 20 bis 50 Fälle für jedes Merkmal rechnen. Und jeder Fall bedeutet Aufwand: Jeder Fall muss einzeln in allen Merkmalen kodiert und eine Bewertung gewonnen werden. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
-
Teil – Fälle der Problemstellung
Wenn man einmal die Auswahl von Kandidatenmerkmalen getroffen hat, muss man herausfinden, wie oft sie unter welchen Umständen in der echten Welt vorzufinden sind. Hierfür sammelt man Material typischer Entscheidungssituationen, z.B. echte Kaufangebote, Videos echter Beratungssituationen oder echte Informationsangebote.
Liegt solches Material vor, sind mit einem systematischen Ansatz möglichst realitätsgetreue Fälle dieser Entscheidungssituationen auszuwählen. Hierfür muss man sowohl berücksichtigen, wie viele Kandidatenmerkmale man untersuchen möchte, aber auch wie selten der Prüfgegenstand ist, also was der Entscheidungsbaum zu identifizieren helfen soll. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
Liegt solches Fallmaterial von typischen Entscheidungssituationen nicht vor, ist die FFT-Methode fallbasierter Merkmalsvalidität nicht geeignet. In einem solchen Fall muss man auf eine andere Methode ausweichen.
-
Teil – Fallbewertungen
Für jeden Fall in Ihrer Datengrundlage müssen Sie wissen oder festlegen, ob das Zielkriterium erfüllt ist oder nicht. Im Fall einer Gesundheitsinformation wäre beispielsweise eine positive Bewertung das Zielkriterium, wenn durch sie eine informierte Entscheidung ermöglicht wird, andernfalls eine negative Bewertung. Ohne diese Basis von bereits entschiedenen Fällen ist kein Modell für zukünftige Entscheidungsunterstützung denkbar. Ein Ansatz wäre, dass Sie jeden Fall testen, d.h. ermitteln, wie er ausgegangen ist. In der Regel ist dieser Aufwand nicht zu leisten, weil es hieße, 500 bis 700 Fälle experimentell zu untersuchen.
Die Alternative ist der „Blick des Experten“, auf welchen der hier vorgestellte Modellansatz von Beginn an abzielte. Mehrere voneinander unabhängige Experten bewerten jeden einzelnen Fall mit Blick auf das Zielkriterium, z.B.: „Ermöglicht diese Gesundheitsinformation eine informierte Entscheidung?“ Die Urteile müssen dann zusammengeführt werden. Der Medianwert über ihre Urteile erweist sich zum Zusammenführen der einzelnen Bewertungen als robuster als arithmetische Mittelwerte. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
B. Wie gehen Sie vor?
Sie müssen nun herausfinden, welche Merkmale die von Ihnen ausgewählten Fälle (z.B. echte Kaufangebote) aufweisen oder nicht aufweisen. Während Sie diese Fälle in Ihren Kandidatenmerkmalen beschreiben, lernen Sie viel über die tatsächliche Prüfbarkeit der Merkmale durch Laien. Es ist anzunehmen, dass Sie sich als Konsequenz bereits einiger Merkmale entledigen, für die eine korrekte Überprüfung durch Verbraucher schwierig gewesen wäre.
Parallel zur Kodierung der Fälle in den Merkmalen sind die Expertenbewertungen „einzusammeln". Hierbei erhalten alle Experten immer nur das Fallmaterial, niemals die Merkmale oder gar die Merkmalskodierung. Ziel ist, die Expertenbewertungen (den Blick des Experten) unabhängig zu modellieren.
Da die Kodierung von zahlreichen Kandidatenmerkmalen sehr aufwendig ist, verspricht ein früher Zeitpunkt einer weiteren Reduzierung der Merkmalsanzahl große Effizienzgewinne. Bevor man allerdings eine Auswahl mithilfe von Laien vornimmt, indem man testet, wie gut sie die Merkmale verstehen, ist eine statistische Antwort in der Regel günstiger und einfacher. Bereits nach 100 Fällen lohnt sich eine einfache statistische Merkmalsselektion. Hierbei stehen verschiedene Werkzeuge zur Verfügung, z.B. das boruta-Paket oder das caret-Paket (beides in der Open-Source-Lösung R implementiert). Mit boruta wird die grundsätzliche Bedeutung der einzelnen Merkmale durch sogenannte Random Forests überprüft. Verhält sich ein Merkmal mit Blick auf die Expertenbewertungen wie eine Zufallszahl, lautet die statistische Empfehlung, es mangels Bedeutung in der weiteren Entwicklung beiseite zu lassen. Auch hier gilt wie bei allen statistischen Ansätzen, die auf Stichproben basieren: Wenn Ihr Hintergrundwissen sagt, dass das Merkmal eigentlich bedeutsam sein sollte, nehmen Sie es eine weitere Runde mit und kodieren es ebenfalls in den nächsten 100 Fällen.
Diesen Vorgang aus Kodieren, Bewerten und statistischer Merkmalsauswahl wiederholen Sie alle 100 Fälle und versuchen so auch das Set der Merkmale handhabbarer zu gestalten. Dies wirkt sich positiv auf den Aufwand zur Kodierung, der Expertenbewertungen und auch der Modellfindung aus.
Wenn sich bei der Merkmalsauswahl nichts mehr ändert, Sie je nach Merkmalsanzahl 500 bis 1000 Fälle bewertet haben oder Sie Gefahr laufen, sechs Merkmale zu unterschreiten, lohnt sich eine Modellierung des Entscheidungsbaums auf Basis dieser Fall-Merkmals-Bewertungs-Profile.
Die Pipeline zur Entwicklung lässt sich in einer vereinfachten Darstellung zusammenfassen:

Die Modellierung aus Baumerstellung und Kreuzvalidierung ist händisch möglich, im Sinne einer effektiven Modellfindung mithilfe der Open-Source-Lösung R jedoch leichter. Neben dem Paket FFTrees (Phillips et al., 2017) können Sie auch eine Weblösung von Evaldas Jablonskis und Uwe Czienskowski unter http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/nutzen. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an. Die Kontaktdaten finden Sie im Reiter Kontakt.
Sie werden einen Fast-and-Frugal Tree (FFT) modellieren mithilfe des Teils der Fälle, den Sie als Trainingsdaten auswählen; oft 50% bis 80% der Fälle. Dieser FFT hat eine gewisse Fähigkeit, richtige Entscheidungen zu fällen (Bewertung). D.h., er wird in der echten Welt Fälle übersehen und bei anderen fehlalarmieren. Um diese Fähigkeit quantifizieren zu können, führen Sie entweder eine statistische Kreuzvalidierung durch (Sie wenden den ermittelten Entscheidungsbaum auf zufällig wiederholt gezogene Fälle an; Testdatenfälle) oder Sie wenden ihn einmal auf eine Sammlung von Fällen mit Bewertungen an, die Sie vor der Modellierung zur Seite gelegt haben (20% bis 50% der Daten). Alternativ können Sie auch noch eine völlig neue Stichprobe von Fällen mit Merkmalskodierungen und Bewertungen sammeln (out-of-sample), auf die Sie den Entscheidungsbaum anwenden (Zusatzaufwand).
Welche Güte ausreichend ist, hängt sehr von den Fehlerarten und den an Fehlentscheidungen geknüpften Kosten ab. Abschließend muss das Modell in der Praxis mit Laien erprobt werden. Hierbei ist eine randomisierte kontrollierte Studie zweckmäßig, bei der man Entscheidungsintentionen von Verbrauchern, denen man den Entscheidungsbaum zur Hand gibt, mit solchen, die nichts oder ein Standardinformationsblatt haben, vergleicht. Wenn Sie bei Güte oder Evaluation Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
- Aikman, D., Galesic, M., Gigerenzer, G., Kapadia, S., Katsikopoulos, K. V., Kothiyal, A., ... & Neumann, T. (2014). Taking uncertainty seriously: Simplicity versus complexity in financial regulation. Bank of England Financial Stability Paper, 28.
- Green, L., & Mehr, D. R. (1997). What alters physicians' decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219–226.
- Jablonskis, E., & Czienskowski, U. (2017). Decision trees online. http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/
- Jenny, M. A., Pachur, T., Williams, S. L., Becker, E., & Margraf, J. (2013). Simple rules for detecting depression. Journal of Applied Research in Memory and Cognition, 2(3), 149–157.
- Luan, S., Schooler, L. J., & Gigerenzer, G. (2011). A signal-detection analysis of fast-and-frugal trees. Psychological Review, 118(2), 316.
- Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352–361.
Wenn Sie ein Verbraucherthema von unserer Internetseite übernehmen möchten, können Sie das über die folgenden drei Wege tun:
- Sie verwenden eine digitale Kopie. Entweder Sie speichern sich direkt eine Grafik bzw. laden unser PDF herunter oder Sie binden die Grafik mittels Link(a href) oder iframe ein.
- Sie ziehen Ihre analoge Kopie und drucken sich unser PDF aus. Die Auflösung ist für Poster und Broschüren geeignet.
- Sie empfehlen die App und verweisen auf den RisikoKompass aus PlayStore und AppStore.
Wenn Sie ein eigenes Modell entwickeln möchten, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
Wir bitten darum, bei der Nutzung der Instrumente den Zuwendungsgeber, das Bundesministerium der Justiz und für Verbraucherschutz, sowie das Harding-Zentrum für Risikokompetenz als verantwortliche Entwickler zu erwähnen.
Die Logos zum Download finden Sie hier.
Im US-Wahlkampf 2016 wurden die 20 erfolgreichsten Falschmeldungen öfter gelikt, geteilt oder kommentiert als die 20 erfolgreichsten Texte von seriösen Medien. Dieses Beispiel zeigt zum einen: Durch das Internet ist es heutzutage viel leichter, schnell Informationen zu verbreiten. Zum anderen sagt es uns: Fake News sind oftmals attraktiver als seriöse Berichterstattung. Das führt zu Fehleinschätzungen, verhärteten Diskussionsfronten und erschwert so den gesellschaftlichen Austausch. Fake News zu erkennen ist nicht immer leicht. In einem ersten Schritt ist es für Sie daher wichtig, zwischen einer Nachricht und einem Meinungstext unterscheiden zu können. Welcher Text gibt Fakten wieder – und welcher nicht? Können Sie eine Satire, einen Kommentar oder eine Glosse erkennen? Unser Entscheidungsbaum als digitale Checkliste leistet Ihnen bei der Prüfung von einem Nachrichtentext Hilfe und warnt Sie, wenn Zweifel daran angebracht sind.
Wann brauche ich die Grafik?
Wenn Sie mutmaßliche Nachrichten suchen, von anderen weitergeleitet bekommen oder in digitalen Gruppen auf sie stoßen, ist eine Prüfung angebracht, ob es sich bei den Texten um ein Meinungsformat oder eine tatsächliche Nachricht handelt.
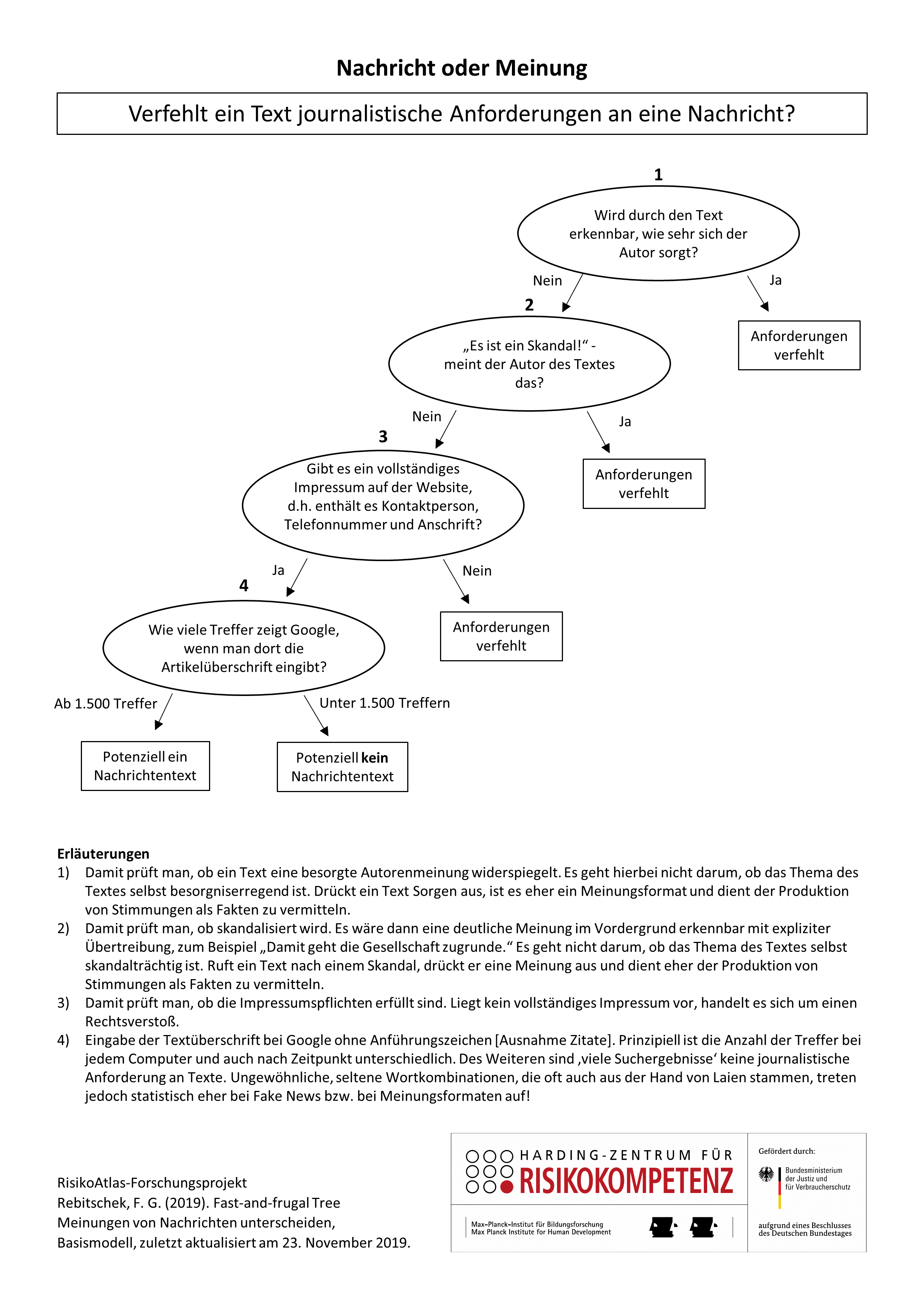
Sie können den vorliegenden Text auch umfänglich prüfen. Beachten Sie jedoch bitte, dass kein Text und auch keine Prüfliste jemals perfekt ist. Mit jedem weiteren Merkmal, welches Sie prüfen, steigt das Risiko einer falschen Einschätzung des Texts.
Weitere Merkmale sind:
- Wird ein Sachverhalt überspitzt dargestellt, ohne Erklärungen dafür zu liefern [NEGATIVES MERKMAL, d.h. wenn es vorkommt, dann spricht das gegen das Erfüllen journalistischer Anforderungen an eine Nachricht]?
- Wird explizit reklamiert, dass der Text ein Geheimnis enthüllt [NEGATIVES MERKMAL]?
- Wird behauptet, dass die anderen Medien die Wahrheit verbergen oder lügen [NEGATIVES MERKMAL]?
- Werden im Text, außerhalb von Zitaten, Personalpronomen wie "Du", "Sie“, "Wir", "Uns", "Euer" verwendet [NEGATIVES MERKMAL]?
Was zeigt die Grafik?
Die Grafik zeigt einen Entscheidungsbaum, mit dem Sie deutschsprachige Texte prüfen können, die den Eindruck einer rein faktenbasierten journalistischen Nachricht vermitteln. Hierbei prüfen Sie, ob der vorliegende Text journalistische Standards an die Textsorte Nachricht erfüllt oder nicht.
Eine Warnung bedeutet hier, dass der Text diese Standards überhaupt nicht erfüllt. Der von Ihnen geprüfte Text informiert nicht im Sinne einer Nachricht. Dafür kann es viele Gründe geben: Es kann eine andere Textsorte sein, z.B. eine, die auf Meinung setzt (Kommentar) oder ein satirisches Format. Der Text kann aber auch einfach unprofessionell gemacht sein oder es sind sogenannte Fake News. Das trifft insbesondere zu, wenn die Emotionen des Lesers absichtlich geweckt werden sollen. In manchen Fällen kann auch der Entscheidungsbaum zu einer falschen Schlussfolgerung gelangen.
Eine Entwarnung bedeutet, dass journalistische Schlüsselanforderungen weitreichend erfüllt werden. Es ist davon auszugehen, dass es sich nicht um Fake News handelt.
Es ist nicht zwingend notwendig, über die Merkmale des Entscheidungsbaums hinaus noch weitere Anforderungen zu prüfen. Untersuchungen der zugrunde liegenden Texte zeigen, dass andere wichtige Anforderungen bzw. Merkmale in der Regel auch erfüllt oder eben nicht erfüllt sind.
Woher stammen die Daten?
Fälle – Welche Texte dienten als Grundlage?
600 Texte deutschsprachiger Internetseiten wurden zusammengetragen. Sie wurden durch Experten vom Harding-Zentrum für Risikokompetenz recherchiert. Da wir uns für die Erkennung von Fake News interessieren, wurde eine themenbasierte Strategie gewählt. Die Themen, zu denen sowohl Nachrichten wie Meinungsformate zu erwarten waren, stammten von Correctiv[1]und von Faktenfinder[2]. Sie wurden danach mit den folgenden Schlagworten recherchiert: „Angela Merkel“, „Flüchtlinge“, „Asyl“, „Migrationshintergrund“, „Chemtrails“, „Kondensstreifen“, „Islam“, „Muslime“, „Israel“, „Juden“, „Krebs“, „Arbeitslose“, „Gender“, „Rußland“, „VW“, „Linksextremismus“, „Autonome“, „Rechtsextremismus“, „Bargeld“, „Klima“. Diese Recherche wurde auf Bing-News, Google-News, Facebook, Twitter und mithilfe von Googles „Autovervollständigen-Funktion“ durchgeführt. Zusätzlich wurde die Stichprobe durch einzelne Texte von Quellen, die als Fake-News-Portale in den klassischen reichweitenstarken Nachrichtenportalen thematisiert wurden, angereichert.
Fernsehempfehlungen und Videos wurden entfernt, Reportagen und Interviews ebenfalls.
Zielbewertung – Wie wurde die Nicht-/Erfüllung journalistischer Anforderungen an eine Nachricht bestimmt?
18 Journalisten mit Berufserfahrung im Print oder Digitalen bewerteten die Fälle.
Jedes Informationsangebot wurde von je drei Experten hinsichtlich der Frage bewertet: „Erfüllt dieser Text die journalistischen Anforderungen an eine Nachricht?“ Ein vierstufiges Antwortformat wurde verwendet. Der Medianwert von je drei Experten wurde als Zielwert für den einzelnen Fall verwendet. Die Experten haben im Rahmen der Studie keinerlei Informationen über die verwendeten Kandidatenmerkmale erhalten.
Die abgeleiteten Warnungen bzw. Entwarnungen erscheinen dann im Entscheidungsbaum, wenn die journalistischen Anforderungen an eine Nachricht im Rahmen dieses Expertenmodells überhaupt nicht bzw. zumindest anteilig erfüllt werden. Eine Begründung wird zusätzlich gegeben.
Kandidatenmerkmale – Welche Merkmale wurden in den Blick genommen?
Basierend auf verschiedenen Quellen (ARD MEDIATHEK, 2017; BR.de, 2017; Brown, 2015; Bundeszentrale für politische Bildung, 2017; Erb, 2017; Focus.de, 2015; Kolonko, 2017; La Roche, 2005; Rack et al., 2017; Shu et al., 2017) wurden 86 Merkmale gesammelt, von denen 50 als prinzipiell durch Laien einschätzbar betrachtet wurden.
Merkmalsauswahl und Modellierung
Die Vorauswahl von Merkmalen hatte das Ziel, die Anzahl der Kandidaten für das Vorhersagemodell zur Unterscheidung von Meinungstexten und Nachrichtentexten zu begrenzen. Die Merkmalsselektion wurde unter zwei Gesichtspunkten durchgeführt: Laienprüfbarkeit und statistische Bedeutung; in sechs Schritten:
- Die Fälle 1–100 wurden von zwei unabhängigen wissenschaftlichen Assistenten in den 50 Merkmalen kodiert, verglichen, diskutiert und harmonisiert. Anschließend wurde eine statistische Merkmalsselektion (anhand von Random Forest Trees mit boruta im Statistikprogramm R) durchgeführt und verschiedene Merkmale aufgrund der Rückmeldungen der Kodierer ausgeschlossen (erwiesen sich in der Praxis als schwierig durch Laien kodierbar). 20 Merkmale verblieben.
- Die Fälle 101–500 wurden von zwei verschiedenen Paaren von wissenschaftlichen Assistenten in 100er-Gruppen kodiert, verglichen, diskutiert und harmonisiert und weitere vier statistische Merkmalsselektionen durchgeführt. 15 Merkmale verblieben.
- Die Fälle 501–600 wurden genutzt, um das Kodierverhalten von Laien gegenüber einem geübten wissenschaftlichen Assistenten zu überprüfen. Jeweils fünf Clickworker erreichten keine zufriedenstellende Übereinstimmung bei fünf Merkmalen. Die statistische Merkmalsselektion brachte keine Veränderung.
Das Modell
Zum oben anzeigten Modell – extreme Meinungsformate filtern.
Das Modell bezieht sich auf Texte, bei denen Experten voll und ganz ausschließen, dass sie journalistischen Anforderungen an eine Nachricht gerecht werden. Zum einen wurde für die Modellidentifikation der recursive-Algorithmus von Marcus Buckmann und Özgür Simşek (Manuskript in Vorbereitung) eingesetzt, zum anderen das Paket FFTrees (Phillips et al., 2017). Hierbei wurde der Algorithmus ifan zur Optimierung auf balanced accuracy eingesetzt.
Wie hoch ist die Qualität der Daten?
Die Daten (gesammelte Fälle der nachrichtenartigen Texte) wurden zwischen 2017 und 2018 gesammelt und in ihren Merkmalen kodiert sowie von Experten bewertet. 588 Fälle waren vollständig. Die Datensätze wurden zufällig in Trainings- (zwei Drittel) und Testdatensets (ein Drittel) aufgeteilt.
Das Modell zur Erkennung von Texten, welche journalistische Anforderungen an eine Nachricht nicht erfüllen, hat folgende Qualität:
Im Rahmen einer Kreuzvalidierung des identifizierten Entscheidungsbaums ergaben sich folgende Gütemaße: balanced accuracy = 0,76; Sensitivität in der Erkennung von Texten, die keinerlei Standards einer Nachricht erfüllen (Anteil von 21% im Testset), von 0,88. Dies bedeutet, dass 88 von 100 solcher Texte, die definitiv keine Nachricht sind, durch den Entscheidungsbaum aufgedeckt werden.
Die Spezifität bei der Bestätigung von Nachrichten und Mischformen liegt bei 0,64.
Entwicklungspotenzial
- Kontinuierliche Weiterentwicklung der Basis von Trainingsdaten aufgrund der Veränderung der Angebotssituation
- Höherer Anteil von laiengesammelten Nachrichtentexten, um dem tatsächlichen Suchverhalten und Auffinden gerecht zu werden
Zur empirischen Evaluation mit Verbrauchern
Alle Forschungsergebnisse zu den Grundlagen und zur Wirksamkeit der RisikoAtlas-Werkzeuge bezüglich Kompetenzförderung, Informationssuche und Risikokommunikation werden mit dem Projekt-Forschungsbericht am 30. Juni 2020 veröffentlicht. Bei vorausgehendem Interesse sprechen Sie uns bitte direkt an (Felix Rebitschek, rebitschek@mpib-berlin.mpg.de).
Quellen
- ARD MEDIATHEK (2017): Fakt oder Fake? Wie man gefälschten Nachrichten auf die Schliche kommt. Verfügbar unter: https://www.ardmediathek.de/tv/neuneinhalb-das-Reportermagazin-f%C3%BCr-Ki/Fakt-oder-Fake-Wie-man-gef%C3%A4lschten-Na/Das-Erste/Video?bcastId=431486&documentId=41134052 (letzter Abruf am 19.06.2018).
- BR.de (2017). So geht Medien (letzter Zugriff, 23.03.2017).
- Brown, P. (2015). Sechs Wege um Falschmeldungen zu entlarven. Der Freitag, 28.10.2015 (letzter Abruf am 23.03.2017).
- Bundeszentrale für politische Bildung (2017). Den Durchblick behalten. So lassen sich Fake News enttarnen, 23.02.2017 (letzter Abruf am 23.03.2017).
- cf. Shu, K., Sliva, A., Wang, S., Tang, J., & Liu, H. (2017). Fake news detection on social media: A data mining perspective. ACM SIGKDD Explorations Newsletter, 19(1), 22–36.
- Erb, S. (2017). So entlarven Sie Fake News, 31.07.2017 (letzter Abruf am 14.2.2017).
- Focus.de (2017). Unseriöse Quellen: So enttarnen Sie Fake News. Online focus, 11.10.2017 (letzter Abruf am 24.03.2017).
- Kolonko (2017). Wie erkenne ich Fake News? Hilfreiche Tipps für die Faktenprüfung. Planet Wissen.
- La Roche, W. V. (2006). Einführung in den praktischen Journalismus. München, List.
- nach Computer + Unterricht 74/2009, S. 43 und FH Hannover: Handbuch zur Recherche. Hannover 2006.
- Rack et al. (2017). Fakt oder Fake? Wie man Falschmeldungen im Internet entlarven kann. klicksafe.de to go.
Datum der letzten Aktualisierung: 27. November 2019