FFT-Methode nach Vorbild
Wenn der Schein trügt – Kundenbewertungen sind mit Vorsicht zu genießen
Mangelt es an belastbaren Daten zum Eintreffen spezifischer Ereignisse oder an Wissen über Entscheidungskonsequenzen, liegt ein Problem der Unsicherheit vor. Bessere Entscheidungen können dabei kaum durch den geübten Umgang mit Statistiken oder ihre transparente Kommunikation erreicht werden. Stattdessen ist die zentrale Fragestellung, wie der einzelne Verbraucher die Unsicherheit in seiner Entscheidungssituation reduzieren kann. Hierbei sind zwei Szenarien zentral:
Wie kann Unsicherheit für Problemstellungen alltagstauglich (schnell, praktisch) reduziert werden, bei denen der Verbraucher auf sich allein gestellt ist?
Wie kann Unsicherheit für Problemstellungen alltagstauglich (schnell, praktisch) reduziert werden, bei denen ein Experte dem Verbraucher Rat gibt?
Warum ist es schwierig, Entscheidungsunterstützung bei Problemen der Unsicherheit zu geben?
Entscheidungsprobleme der Unsicherheit zeichnen sich durch einen Mangel an belastbaren Daten aus. Dadurch ist eine direkte Auswahl der besten Entscheidungsoption im Grunde ausgeschlossen. Die Unterstützung besteht darin, entscheidende Strategien zu kennen, um Unsicherheit zu reduzieren. Was muss ich fragen, um die Auswahl möglicher Informationen bzw. Optionen zu reduzieren? Wonach muss ich suchen? Was muss ich prüfen, um unpassende Optionen auszusortieren, welche die Mindestanforderungen nicht erfüllen?
Im Gegensatz zu Verbrauchern sind Experten in einem bestimmten Fachgebiet in der Lage, anhand weniger heuristischer Merkmale objektive Standardunterschreitungen bei einem Entscheidungsproblem zu identifizieren. Mithilfe einer Analyse von konkreten Entscheidungssituationen von Verbrauchern werden mögliche Expertenheuristiken in Entscheidungsbäume destilliert. Diese fassen das auf Erfahrung basierte Bauchgefühl der Experten zusammen und leihen dem Verbraucher eine robuste Expertise, mit der er, dem Experten ähnlich, die Spreu vom Weizen zu trennen vermag.
Dies ist nicht nur für Fragestellungen bedeutsam, bei denen Verbraucher auf sich allein gestellt sind. Auch für Beratungssituationen lassen sich mögliche Entscheidungsheuristiken in Entscheidungsbäumen kombinieren: Hier geht es darum, dem Berater die wichtigsten Fragen zu stellen, um diese Situation robust einschätzen zu können.
Geeignete Entscheidungsbäume, die transparent, für Verbraucher nachvollziehbar und zugleich von hoher Güte sein können, sind die Fast-and-Frugal Trees (FFTs). Diese FFTs stellen eine Abfolge von zu prüfenden Merkmalen dar (Martignon et al., 2008). Es gibt immer nur eine Abzweigung (Stopp) oder man kommt zum nächsten Prüfmerkmal, aber es gibt keine weiteren Verzweigungen (s.u. das Themenbeispiel). Dies unterscheidet die FFTs von üblichen Entscheidungsbäumen. Erst beim letzten Merkmal in der Kette gibt es zwei Abzweigungen.
Es wurde gezeigt, dass FFTs in verschiedensten Entscheidungssituationen unter Unsicherheit schnelle und zuverlässige Entscheidungen ermöglichen, u.a. in der Psychiatrie, in der Anästhesiologie, aber auch in der Finanzwelt (Aikman et al., 2014; Green & Mehr, 1997; Jenny et al., 2013). FFTs lassen sich in Form einer grafisch aufgearbeiteten, einfachen Baumstruktur sowohl digital (z.B. App, Internetseite) als auch analog zu den Verbrauchern bringen (z.B. auf Postern oder in Broschüren). Somit sind sie ein evidenzbasiertes Instrument zur Entscheidungsunterstützung, das einfach zu implementieren ist. Im RisikoAtlas-Projekt wurde es erstmals für die alltägliche Verbraucherpraxis entwickelt und umgesetzt. Der Einsatz der FFTs ist zudem lebensdienlich, da ihre Benutzung Fähigkeiten trainiert. Die Verwendung der FFTs erleichtert das Verinnerlichen von Schlüsselmerkmalen für Problemstellungen und regt kritisches Denken an.
Die Reihenfolge der Merkmale in einem FFT ist kritisch und muss aufwendig im Vorhinein ermittelt werden. Hierbei sind manuelle, aber auch komplexere Ansätze mithilfe der Methoden des maschinellen Lernens vorhanden. Einmal statistisch ermittelt, ermöglicht diese Merkmalskombination einem Verbraucher, Entscheidungsoptionen robust zu klassifizieren (z.B. dahingehend, ob eine informierte Entscheidung ermöglicht wird), indem er die Ausprägung der Merkmale eigenständig überprüft.
Wie konstruiert man einen Entscheidungsbaum für ein Verbraucherproblem – die FFT-Methode Modellvorbild
A. Was benötigen Sie?
Für die evidenzbasierte Entwicklung von FFTs benötigt man bei allen Ansätzen (inkl. der FFT-Methode Modellvorbild) eine Datenbasis mit drei Teilen: Merkmale des Problems, Fälle der Problemstellung und die jeweilige Fallbewertung. Die FFT-Methode Modellvorbild ist dann hilfreich, wenn es bereits ein Modell des interessierenden Entscheidungsziels gibt, z.B. einen Entscheidungsbaum anderer Forscher (Banerjee et al., 2017).
- Teil – Merkmale des Problems
Liegt bereits ein Modell vor, sind in der Regel auch die verwendeten Merkmale bekannt (Ausnahme stellen bestimmte Deep-Learning-Ansätze dar, die bei Verbraucherproblemen jedoch bis 2019 keine besondere Verbreitung haben). Jedes Kandidatenmerkmal muss durch einen Laien verstehbar und prüfbar sein. Gerade international entwickelte Modelle verlangen eine gesonderte Prüfung nicht nur hinsichtlich der deutschen Sprache, sondern auch des kulturellen Transfers auf die deutsche Verbraucherwelt und Gestaltung von Informationen oder Beratung.
- Teil – Fälle der Problemstellung
Sofern bereits ein Modell vorliegt, ist für dessen empirische wissenschaftliche Überprüfung ein Testdatensatz erforderlich, z.B. eine Sammlung echter Entscheidungssituationen wie echte Kaufangebote, Videos echter Beratungssituationen oder echte Informationsangebote.
Mit Blick auf die Anzahl der Kandidatenmerkmale sowie auf die Seltenheit des Prüfgegenstands (was soll der Entscheidungsbaum zu identifizieren helfen) sind mit einem systematischen Ansatz möglichst ökologisch valide Stichproben von Entscheidungssituationen auszuwählen. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
- Teil – Fallbewertungen
Um das Vorbildmodell zu testen, müssen Sie für jeden Fall in Ihrer Datengrundlage wissen oder festlegen, ob das Zielkriterium erfüllt ist oder nicht. Im Fall einer Gesundheitsinformation wäre beispielsweise eine positive Bewertung das Zielkriterium, wenn durch sie eine informierte Entscheidung ermöglicht wird, andernfalls eine negative Bewertung.
Ohne diese Basis von bereits entschiedenen Fällen können Sie das Vorbildmodell weder testen noch ein eigenes Modell verwenden, um das Vorbild „nachzumodellieren".
Ein Ansatz wäre, dass Sie jeden Fall testen, d.h. ermitteln, wie er ausgegangen ist. Sehr oft ist dieser Aufwand nicht zu leisten, denn das hieße, 500 bis 700 Fälle experimentell zu untersuchen. Die Alternative ist dann der „Blick des Experten“, auf welchen der hier vorgestellte Modellansatz von Beginn an abzielte. Mehrere voneinander unabhängige Experten bewerten jeden einzelnen Fall mit Blick auf das Ziel der Entwicklung, z.B.: „Ermöglicht diese Gesundheitsinformation eine informierte Entscheidung?“ Der Medianwert über ihre Urteile erweist sich zum Zusammenführen der einzelnen Bewertungen als robuster als arithmetische Mittelwerte. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
B. Wie gehen Sie vor?
Während Sie die Fälle Ihres Testdatensatzes in den Merkmalen des Vorbildmodells kodieren lassen, lernen Sie viel über die begrenzte Prüfbarkeit mancher Merkmale durch Laien. Es ist jedoch anzunehmen, dass Sie alle Merkmale behalten, die das Vorbildmodell ausmachen, um dieses testen zu können. Aus demselben Grund entfällt auch eine statistische Merkmalsauswahl.
Parallel zur Kodierung der Fälle in den Merkmalen sind die Fälle zu testen bzw. die Expertenbewertungen für Ihren Testdatensatz „einzusammeln". Hierbei erhalten alle Experten immer nur das Fallmaterial, niemals die Merkmale oder gar die Merkmalskodierung. Ziel ist, die Expertenbewertungen unabhängig zu modellieren (den Blick des Experten).
Dieser Vorgang aus Kodieren und Bewerten lässt sich – je nach Merkmalsanzahl – nach 200 bis 600 Fällen beenden, und man testet das Vorbildmodell an dem selbst generierten Datensatz.
Die Pipeline zur Entwicklung lässt sich in einer stark vereinfachten Darstellung folgendermaßen zusammenfassen:
Die Modellierung aus Baumerstellung und Kreuzvalidierung ist händisch möglich, im Sinne einer effektiven Modellfindung mithilfe der Open-Source-Lösung R jedoch leichter. Neben dem Paket FFTrees (Phillips et al., 2017) können Sie auch eine Weblösung von Evaldas Jablonskis und Uwe Czienskowski unter http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/nutzen. Wenn Sie hierbei Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
Sie werden das Vorbildmodell manuell konstruieren und am generierten Testdatensatz prüfen. Dabei führen Sie eine Kreuzvalidierung durch, Sie wenden das Vorbildmodell auf zufällig wiederholt gezogene Fälle aus dem Testdatensatz an.
Zusätzlich oder alternativ würden Sie einen Fast-and-Frugal Tree (FFT) modellieren, der das Vorbildmodell imitieren soll, aber aus Verbrauchersicht wahrscheinlich einfacher ist. Dann würden Sie einen Teil des gewonnenen Datensets als Trainingsdaten auswählen; oft 33% oder 50% der Fälle. Dieser FFT hat eine gewisse Güte hinsichtlich des Aufspürens Ihres Zielmerkmals (Bewertung). D.h., er wird in der echten Welt Fälle übersehen und bei anderen fehlalarmieren. Um diese Güte quantifizieren zu können, führen Sie eine statistische Kreuzvalidierung durch oder Sie wenden ihn einmal auf eine Sammlung von Fällen mit Bewertungen an, die Sie vor der Modellierung zur Seite gelegt haben. Alternativ können Sie auch noch eine völlig neue Stichprobe von Fällen mit Merkmalskodierungen und Bewertungen sammeln (out-of-sample), auf die Sie den Entscheidungsbaum anwenden (Zusatzaufwand).
Welche Güte ausreichend ist, hängt sehr von den Fehlerarten und die an den Irrtum geknüpften Kosten ab. Abschließend müssen das Vorbildmodell und ggf. der neue FFT in der Praxis mit Laien erprobt werden. Hierbei ist eine randomisierte kontrollierte Studie zweckmäßig, bei der man Entscheidungsintentionen von Verbrauchern, denen man den Entscheidungsbaum zur Hand gibt, mit solchen, die nichts oder ein Standardinformationsblatt haben, vergleicht. Wenn Sie bei Güte oder Evaluation Unterstützung benötigen, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns. Die Kontaktdaten finden Sie im Reiter Kontakt.
- Aikman, D., Galesic, M., Gigerenzer, G., Kapadia, S., Katsikopoulos, K. V., Kothiyal, A., ... & Neumann, T. (2014). Taking uncertainty seriously: Simplicity versus complexity in financial regulation. Bank of England Financial Stability Paper, 28.
- Banerjee, S., Chua, A. Y., & Kim, J. J. (2017). Don't be deceived: Using linguistic analysis to learn how to discern online review authenticity. Journal of the Association for Information Science and Technology, 68(6), 1525–1538.
- Green, L., & Mehr, D. R. (1997). What alters physicians' decisions to admit to the coronary care unit?. Journal of Family Practice, 45(3), 219–226.
- Jablonskis, E., & Czienskowski, U. (2017). Decision trees online. http://www.adaptivetoolbox.net/Library/Trees/TreesHome#/
- Jenny, M. A., Pachur, T., Williams, S. L., Becker, E., & Margraf, J. (2013). Simple rules for detecting depression. Journal of Applied Research in Memory and Cognition, 2(3), 149–157.
- Luan, S., Schooler, L. J., & Gigerenzer, G. (2011). A signal-detection analysis of fast-and-frugal trees. Psychological Review, 118(2), 316.
- Martignon, L., Katsikopoulos, K. V., & Woike, J. K. (2008). Categorization with limited resources: A family of simple heuristics. Journal of Mathematical Psychology, 52(6), 352–361.
Wenn Sie ein Verbraucherthema von unserer Internetseite übernehmen möchten, können Sie das über die folgenden drei Wege tun:
- Sie verwenden eine digitale Kopie. Entweder Sie speichern sich direkt eine Grafik bzw. laden unser PDF herunter oder Sie binden die Grafik mittels Link(a href) oder iframe ein.
- Sie ziehen Ihre analoge Kopie und drucken sich unser PDF aus. Die Auflösung bzw. die vektorbasierte Grafik ist für Poster und Broschüren geeignet.
- Sie empfehlen die App und verweisen auf den Risikokompass aus PlayStore und AppStore.
Wenn Sie ein eigenes Modell entwickeln möchten, konsultieren Sie bitte den Abschlussbericht zum RisikoAtlas-Projekt ab Juli 2020 oder richten Sie eine Anfrage an uns.Die Kontaktdaten finden Sie im Reiter Kontakt.
Wir bitten darum, bei der Nutzung der Instrumente den Zuwendungsgeber, das Bundesministerium der Justiz und für Verbraucherschutz, sowie das Harding-Zentrum für Risikokompetenz als verantwortliche Entwickler zu erwähnen.
Die Logos zum Download finden Sie hier.
Nehmen wir an, Sie brauchen einen neuen Wanderrucksack. Eigentlich kennen Sie sich mit Rucksäcken gar nicht aus. Online haben Sie die breiteste Auswahl, also beschließen Sie, das Produkt im Internet zu kaufen. Die Beschreibungen der Hersteller klingen für Sie alle gleich und versprechen Ähnliches. Da Sie wirklich nicht wissen, woran Sie sich beim Kauf orientieren sollen, filtern Sie nach Kundenbewertungen. Denn ein Produkt, das nur Fünf-Sterne-Ratings hat, kann ja schließlich kein Fehlgriff sein. Oder?
Beim Onlineshopping sind Kundenbewertungen das wichtigste Entscheidungskriterium – noch vor dem Preisvergleich oder der Empfehlung von Freunden oder Verwandten. Doch allzu oft sind diese Bewertungen gefälscht. Schätzungsweise jede fünfte Bewertung ist nicht echt. Und das Bewertungs-Business boomt. Bei einschlägigen Agenturen kostet eine gekaufte Bewertung nicht viel mehr als 10 Euro. Doch zum Glück es gibt einige Kriterien, an denen man falsche Empfehlungen erkennen kann. Unser Entscheidungsbaum als digitale Checkliste soll Ihnen dabei helfen, echte Bewertungen von Fakes zu unterscheiden.
Für wen ist der Entscheidungsbaum geeignet
Für alle Verbraucher, die online einkaufen.
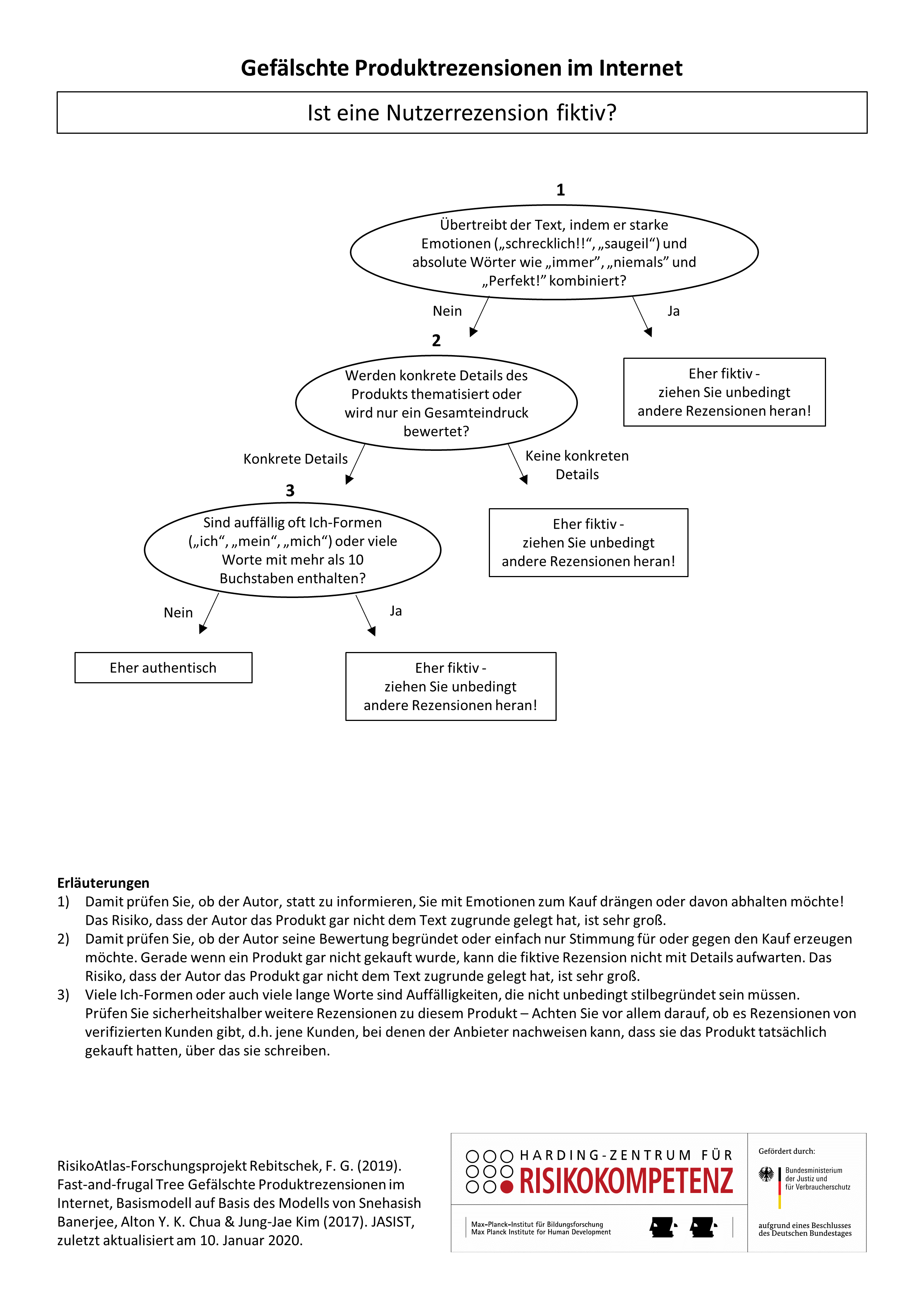
Sie können die Nutzerrezension auch weitergehend prüfen.
Beachten Sie jedoch bitte, dass kein Test und auch keine Prüfliste jemals perfekt ist. Mit jedem weiteren Merkmal, welches Sie prüfen, steigt das Risiko einer falschen Einschätzung des Texts. Sie könnten zum Beispiel die Nutzerrezensionen und Nutzerbewertungen mithilfe eines automatischen Werkzeugs prüfen lassen: www.reviewmeta.com. Obwohl die Seite in englischer Sprache ist, können Sie dort zum Beispiel deutschsprachige Amazon-Produktlinks prüfen. Sie können so nachvollziehen, wie hoch die echte Bewertung ist und welche Rezensionen dort als nicht vertrauenswürdig gelten.
Woher stammen die Daten?
Fälle – Welche dienten als Grundlage?
Daten aus einer Studie des Harding-Zentrums für Risikokompetenz dienten als Testdatensatz.
Zielbewertung – Wie wurden die Produktrezensionen voreingeschätzt?
Produktrezensionen wurden in einer Studie des Harding-Zentrums für Risikokompetenz für die Modellierung und eine weitere Studie künstlich von Laien angefertigt.
Kandidatenmerkmale – Welche Merkmale wurden in den Blick genommen?
Es wurden die drei Merkmale des Modells von Banerjee et al. (2017) verwendet.
Merkmalsauswahl und Modellierung
Es wurden die drei Merkmale des Modells von Banerjee et al. (2017) verwendet.
Das Modell
Für den Modelltest wird das Paket FFTrees eingesetzt (Phillips et al., 2017). Hierbei wurde der Algorithmus ifan zur Optimierung auf balanced accuracy eingesetzt.
Wie hoch ist die Qualität der Daten?
Da die Evaluationsstudien bis Dezember 2019 laufen, können hier noch keine Vorhersagen für die Güte des englischsprachig entwickelten Modells für deutschsprachige Produktrezensionen gemacht werden.
Entwicklungspotenzial
Kontinuierliche Weiterentwicklung der Basis von Trainingsdaten aufgrund der Veränderung der Marktsituation.
Zur empirischen Evaluation mit Verbrauchern
Alle Forschungsergebnisse zu den Grundlagen und zur Wirksamkeit der RisikoAtlas-Werkzeuge bezüglich Kompetenzförderung, Informationssuche und Risikokommunikation werden mit dem Projekt-Forschungsbericht am 30. Juni 2020 veröffentlicht. Bei vorausgehendem Interesse sprechen Sie uns bitte direkt an (Felix Rebitschek, rebitschek@mpib-berlin.mpg.de).
Quellen
• Banerjee, S., Chua, A. Y., & Kim, J. J. (2017). Don't be deceived: Using linguistic analysis to learn how to discern online review authenticity. Journal of the Association for Information Science and Technology, 68(6), 1525-1538.
• Phillips, N. D., Neth, H., Woike, J. K., & Gaissmaier, W. (2017). FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgment and Decision making, 12(4), 344-368.
Datum der letzten Aktualisierung: 27. November 2019.